











Large language models are now the default interface for search, coding help, and customer support. Most explanations still rely on analogies like “it’s just autocomplete,” which is technically true but doesn’t explain much. It doesn’t show why these systems can write contracts, debug code, or fail in consistent ways. To understand that, you need the real mechanics: tokenization, transformer attention, and the training pipeline that shapes behavior. These determine both what the models can do and how they break.
The field is also moving quickly. As of mid-2026, publicly available production models include Anthropic’s Claude Opus 4.8 and OpenAI’s GPT-5.5. However, these are not the upper limit of capability. Anthropic has indicated that its most advanced system, Claude Mythos Preview, is still unreleased and is being tested privately with select partners under Project Glasswing while safety work continues.
That gap is interesting, but the more important constant is the underlying architecture: the transformer, introduced in 2017. This design is shared across nearly all modern large language models. Understanding it helps explain why these systems behave consistently across different providers and model versions.
From Text to Tokens: The Input Problem
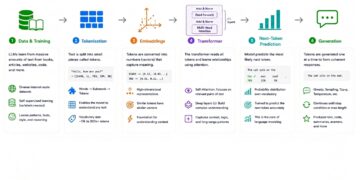
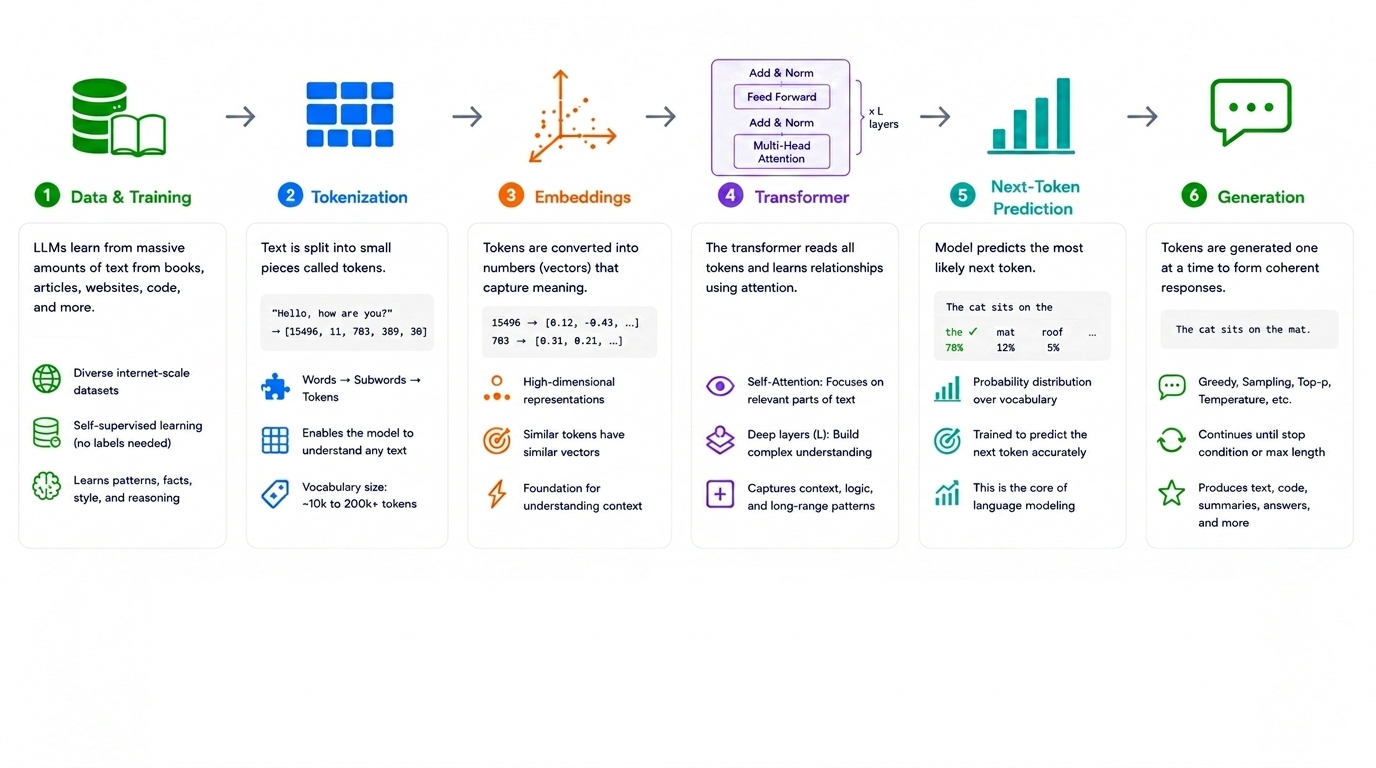
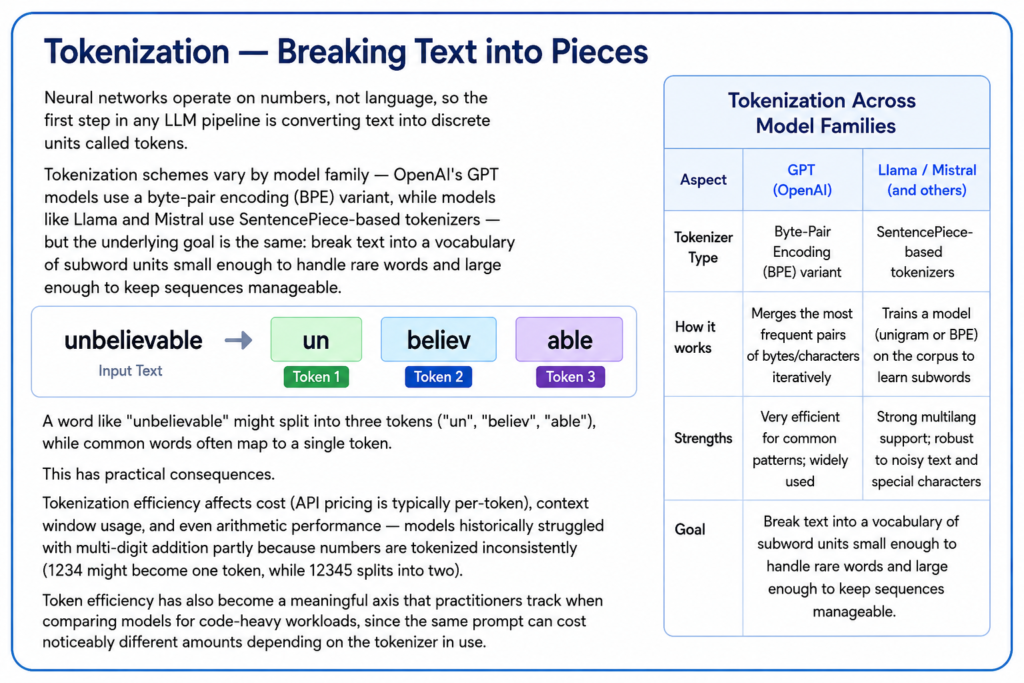
Neural networks operate on numbers, not language, so the first step in any LLM pipeline is converting text into discrete units called tokens. Tokenization schemes vary by model family — OpenAI’s GPT models use a byte-pair encoding (BPE) variant, while models like Llama and Mistral use SentencePiece-based tokenizers — but the underlying goal is the same: break text into a vocabulary of subword units small enough to handle rare words and large enough to keep sequences manageable.
A word like “unbelievable” might split into three tokens (“un”, “believ”, “able”), while common words often map to a single token. This has practical consequences. Tokenization efficiency affects cost (API pricing is typically per-token), context window usage, and even arithmetic performance — models historically struggled with multi-digit addition partly because numbers are tokenized inconsistently (1234 might become one token, while 12345 splits into two). Token efficiency has also become a meaningful axis that practitioners track when comparing models for code-heavy workloads, since the same prompt can cost noticeably different amounts depending on the tokenizer in use.
The Transformer Architecture: Why Attention Matters
The architectural breakthrough underlying every major LLM since 2018 — GPT, Claude, Gemini, Llama — is the transformer, introduced in the landmark 2017 paper “Attention Is All You Need” by Vaswani et al. at Google. Before transformers, language models relied on recurrent neural networks (RNNs and LSTMs), which processed text sequentially and struggled to maintain context over long passages.
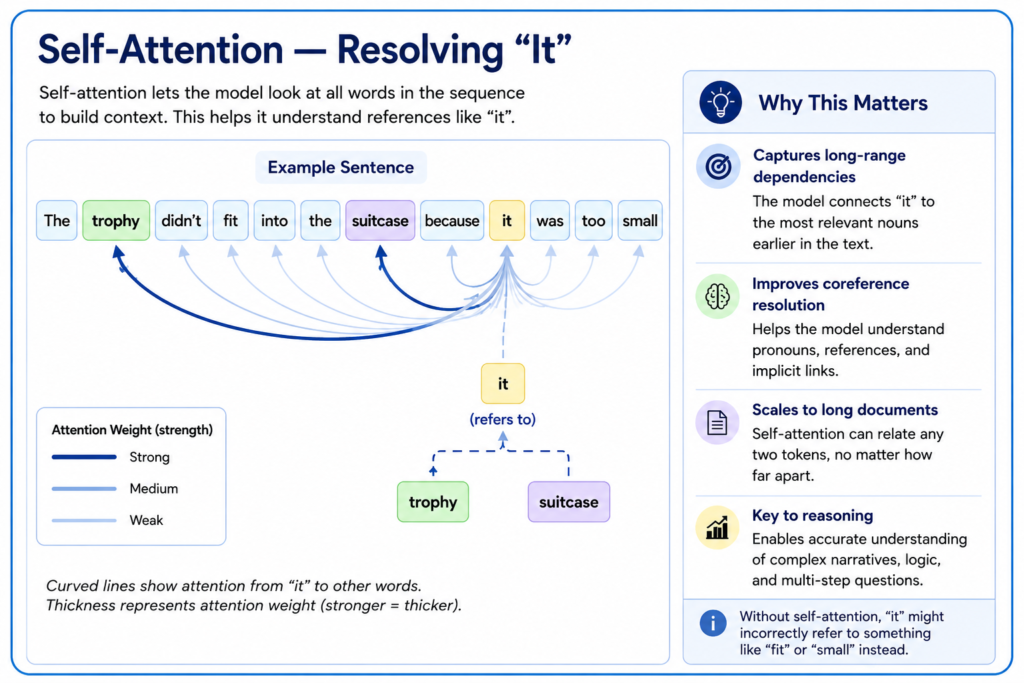
The transformer’s core mechanism, self-attention, allows the model to weigh the relevance of every other token in the input when processing a given token, regardless of distance. Consider the sentence: “The trophy didn’t fit into the suitcase because it was too small.” Resolving what “it” refers to requires connecting “it” back to “trophy” or “suitcase” across several intervening words. Attention layers compute these relationships directly, assigning higher weights to the tokens most relevant to disambiguation.
This parallel processing of relationships — rather than sequential reading — is also why transformers scale efficiently on GPU and TPU hardware, which is a major reason they displaced RNN-based approaches even before their accuracy advantages became clear.
What Training Actually Optimizes For
Pretraining a model like Claude Opus 4.8 or GPT-5.5 involves a deceptively simple objective: given a sequence of tokens, predict the next one. This is repeated across trillions of tokens drawn from web text, books, code repositories, and other sources. The model adjusts billions of internal parameters to minimize the gap between its predictions and the actual next token.
This process does not store facts in any retrievable, database-like form. Instead, statistical regularities — “Paris” frequently follows “The capital of France is,” programming syntax follows consistent patterns, certain reasoning structures recur across mathematical proofs — become encoded as relationships between parameters. This distinction matters practically: it explains why models can generate plausible-sounding but incorrect information (hallucination) with the same fluency as correct information. The model has learned what sounds statistically appropriate, not what is factually verified.
This is also why benchmark scores, whatever model they’re attached to, measure the downstream products of this training process rather than the process itself. Knowing what a model scores on a reasoning benchmark tells you less than understanding why it scores that way — and, increasingly, less than knowing whether the score reflects the most capable system a lab has actually built versus the version it has chosen to make broadly available.
Fine-Tuning and Alignment: Why Raw Models Aren’t Chatbots
A pretrained model is not yet a usable assistant. It is a highly capable text-completion engine that, given a question, might just as easily generate a list of similar questions as an answer. Converting this into a conversational assistant requires additional training stages.
Supervised fine-tuning (SFT) trains the model on curated examples of desired input-output behavior — question-answer pairs, instructions followed correctly, and so on.
Reinforcement learning from human feedback (RLHF), first described at scale in Ouyang et al. (2022) “Training language models to follow instructions with human feedback”, further shapes outputs by training a reward model on human preference rankings and using that signal to adjust the base model’s behavior.
More recent variants include reinforcement learning from AI feedback (RLAIF) and Anthropic’s Constitutional AI approach, originally published as a 2022 research paper. Anthropic significantly revised this framework on January 21–22, 2026, publishing a new constitution for Claude that shifts from listing standalone rules toward explaining the reasoning behind each principle, organized around a tiered priority structure (safety, ethics, compliance, helpfulness).
The revision has drawn substantial attention from AI governance researchers, including analysis from outlets such as Lawfare and the Bloomsbury Intelligence and Security Institute, examining what a published “constitution” means in practice — and how it interacts with separate questions like government contracting terms, where Anthropic’s commitments and a customer’s requirements don’t always align.
These alignment choices are why different models from the same base architecture can behave very differently in production. The Claude Opus 4.8 system card provides Anthropic’s own documentation of how these decisions were applied — a level of transparency that is itself part of the trust signal these cards are designed to establish.
Where the Approach Breaks Down
Several limitations follow directly from the prediction-based architecture rather than being incidental bugs.
Hallucination is structural, not occasional. Because the model generates the statistically likely continuation rather than retrieving verified facts, confident-sounding fabrications are an expected output mode, particularly for niche facts, citations, and numerical details that appeared rarely or inconsistently in training data. This was formally characterized in Maynez et al. (2020) and remains an active area of research even in 2026 frontier models.
Context window limits constrain reasoning over long documents. Even models with very large context windows show degraded attention to information in the middle of long contexts — a phenomenon documented in Liu et al. (2023), “Lost in the Middle”. This continues to show up in practical testing of current-generation models, even as raw context window sizes have grown into the millions of tokens.
Knowledge cutoffs create a moving target. Because pretraining is a snapshot of data up to a certain date, models cannot natively answer questions about events after that cutoff without external tools like web search or retrieval-augmented generation (RAG). The release cadence since 2025 — Claude Opus 4.7 in April 2026, Claude Opus 4.8 in late May 2026, and frequent updates from competing labs — means models are routinely trained on data that already omits significant recent developments by the time they ship.
Reasoning is pattern-matched, not derived. Multi-step reasoning capabilities that emerged in larger models — sometimes called “chain-of-thought” reasoning, studied in Wei et al. (2022) — resemble human reasoning in output but arise from exposure to enormous volumes of worked examples. This is part of why these models can fail on problems that are trivial for a calculator but unusual in phrasing, even as headline benchmark scores continue to improve.

Practical Implications
For anyone evaluating or deploying these systems, the architecture suggests a few concrete takeaways. Tasks involving pattern transformation — summarization, code translation, drafting based on a template — tend to align well with how these models actually operate. Tasks requiring verified factual recall, especially of recent or niche information, benefit substantially from pairing the model with retrieval systems rather than relying on parametric memory alone.
Third-party benchmark and comparison sites can be a useful input when choosing between models, particularly when they account for pricing and latency alongside raw scores. But it’s worth treating this content as one input among several rather than as authoritative: much of it is produced quickly after each release, optimized to rank for “Model X vs Model Y” searches, and varies widely in methodology and rigor. It’s generally more useful for narrowing options than for settling them — and it’s a different category of source from primary documentation, system cards, and peer-reviewed research, even when it cites those sources itself.
And outputs that “sound right” should always be weighted accordingly: fluency is not a proxy for accuracy, and both are produced by exactly the same statistical process.
The transformer architecture and the training pipeline built around it have proven remarkably general-purpose, powering everything from chatbots to coding agents to multimodal systems that process images and audio. But the underlying mechanism — predicting the next token based on learned statistical patterns — remains unchanged across every model in this piece, from the publicly available Opus and GPT tiers to the more advanced systems labs are still holding back. Understanding it is the most reliable way to anticipate both what these systems can do well and where they are likely to fail.
📚 Sources & Further Reading
Primary research, technical documentation, safety research, and governance analysis referenced throughout this guide.
🧠 Foundational Research Papers
-
Vaswani et al. (2017)
Attention Is All You Need The original Transformer architecture paper (Google Brain). -
Ouyang et al. (2022)
Training Language Models to Follow Instructions with Human Feedback Introduced InstructGPT and modern RLHF training (OpenAI). -
Bai et al. (2022)
Constitutional AI: Harmlessness from AI Feedback Anthropic’s alignment framework. -
Wei et al. (2022)
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models Foundational reasoning research (Google Brain). -
Liu et al. (2023)
Lost in the Middle Research on long-context performance (Stanford / UC Berkeley). -
Maynez et al. (2020)
On Faithfulness and Factuality in Abstractive Summarization Key hallucination and factuality research. -
Sennrich et al. (2016)
Neural Machine Translation of Rare Words with Subword Units Introduced BPE tokenization. -
Brown et al. (2020)
Language Models are Few-Shot Learners The GPT-3 scaling paper. -
Hoffmann et al. (2022)
Training Compute-Optimal Large Language Models The Chinchilla scaling laws (DeepMind).
📖 Official Documentation & Technical Reports
- Anthropic — Claude Opus 4.8 System Card (May 2026)
- Anthropic — Claude’s New Constitution (January 22, 2026)
- Anthropic — Introducing Claude Opus 4.7 (April 16, 2026)
- Anthropic — Claude Model Specification
- OpenAI — GPT-4 Technical Report (2023)
- Google DeepMind — Gemini Technical Report (2023)
- Meta AI — LLaMA 2 Technical Report (2023)
🛡️ Alignment & Safety Research
-
Christiano et al. (2017)
Deep Reinforcement Learning from Human Preferences -
Perez et al. (2022)
Red Teaming Language Models with Language Models -
Bowman et al. (2022)
Measuring Progress on Scalable Oversight for Large Language Models
⚖️ Governance Commentary
-
Lawfare
Interpreting Claude’s Constitution -
Bloomsbury Intelligence & Security Institute
Claude’s New Constitution: AI Alignment, Ethics, and the Future of Model Governance
📊 Background Reading
- Stanford HAI — Artificial Intelligence Index Report 2024
- MIT Technology Review — The Inside Story of How ChatGPT Was Built
- Anthropic Research Blog — Ongoing Safety & Capability Research
ℹ️ Note on Sourcing
This bibliography intentionally separates primary sources (research papers, technical reports, system cards, and official model documentation) from commentary and secondary analysis.
Comparison articles, benchmark blogs, and “Model X vs Model Y” posts can help narrow options, but they often use inconsistent methodologies and are frequently produced for SEO purposes. They should not be treated as equivalent to peer-reviewed research, technical reports, or official documentation.
❓ Frequently Asked Questions
Common questions about large language models, transformers, hallucinations, context windows, and AI alignment.
A token is a subword unit a model actually processes — not the same as a word. Common words often map to one token, while longer or rarer words split into multiple pieces (e.g., “unbelievable” → “un” + “believ” + “able”). This affects API costs, context window usage, and even how well a model handles numbers.
Because they generate the statistically most likely next word, not retrieved facts. The model has no internal database to check against — it produces fabrications with the same fluency as accurate information, especially for niche facts, citations, or numbers that appeared rarely in training data.
Introduced in 2017’s Attention Is All You Need, the transformer’s self-attention mechanism lets a model weigh the relevance of every other token when processing a given token — regardless of distance. This is why models can resolve references like “it” across a sentence and scale efficiently on GPU and TPU hardware.
After pretraining, models go through supervised fine-tuning (SFT), RLHF, and approaches like Constitutional AI that shape tone, safety behavior, and response style. These alignment choices account for many behavioral differences between models.
Not entirely. Even models with very large context windows can show degraded attention to information buried in the middle of long inputs — a documented phenomenon that persists even as context sizes grow dramatically.
Pretraining is a snapshot up to a certain date (the knowledge cutoff). Anything after that requires external tools such as web search or retrieval-augmented generation (RAG).
They’re strongest at pattern-transformation tasks such as summarization, drafting, coding assistance, and content generation. For verified facts, especially recent or niche information, pair the model with retrieval systems and authoritative sources rather than relying solely on model memory.








{kind=link}