











| Published: June 15, 2026 | Last updated: June 15, 2026
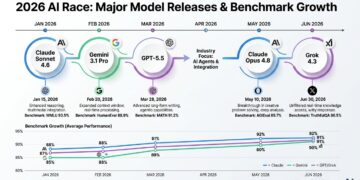
The pace of AI development in 2026 has been genuinely unlike anything the industry has seen before. According to AI Flash Report, which tracks every major model launch, new AI models are now arriving roughly every two days — a release cadence that has made keeping up feel nearly impossible for developers and businesses alike.
But beyond the volume of releases, something more significant is happening. The models shipping in 2026 are not incremental chatbot upgrades. They are autonomous systems capable of writing and debugging entire codebases, conducting multi-hour research workflows, operating software interfaces, and making tool-use decisions with minimal human input. The benchmark scores confirm it: we are watching a genuine generational shift in AI capability.
This article covers the biggest verified model releases and updates of 2026, with real benchmark figures, confirmed pricing, and a clear explanation of what each release actually changes for developers and businesses.
Anthropic: Claude Opus 4.8 Leads on Agentic Coding, While Sonnet 4.6 Becomes the Developer Default
Anthropic has had an unusually productive 2026. The company shipped Claude Sonnet 4.6 on February 17, then Claude Opus 4.7 in April, and most recently Claude Opus 4.8 on May 28 — just 41 days after Opus 4.7, according to coverage from AlphaTechFinance.
Claude Opus 4.8
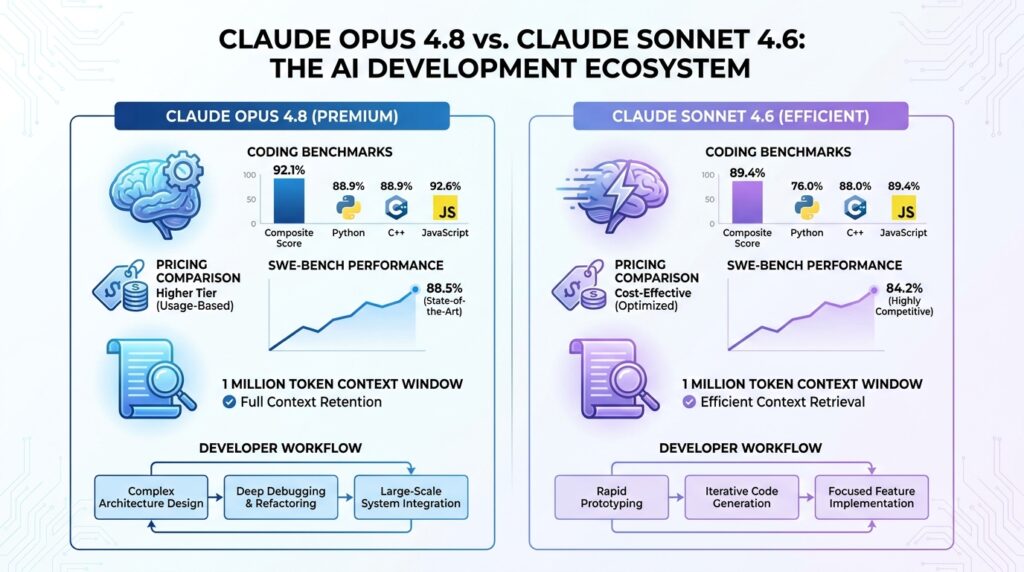
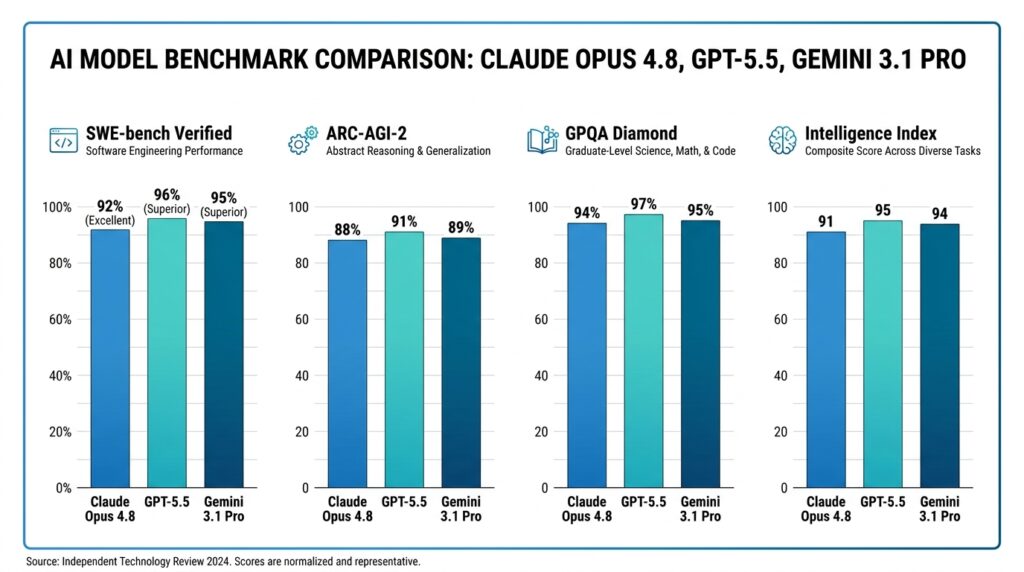
Anthropic’s current flagship scores 88.6% on SWE-bench Verified as of June 2026, per Artificial Analysis’s independent benchmarking — the most rigorous real-world software engineering benchmark currently in wide use. That puts it significantly ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%) on the same test. Pricing is listed at $5 per million input tokens and $25 per million output tokens on Anthropic’s official pricing page — verify current rates before budgeting, as API pricing updates frequently.
Two features shipped with this release that matter for production pipelines:
Dynamic Workflows allow parallel subagents to run simultaneously on complex tasks. In practice, this means a single high-level instruction can spawn coordinated sub-processes — for example, one agent researching dependencies while another drafts the implementation — rather than running each step sequentially. For long agentic tasks, this compresses wall-clock time meaningfully.
Effort-control lets developers dial down computational intensity for simpler operations. On straightforward tasks like summarization or single-file edits, reducing effort level can cut latency and cost without meaningfully degrading output quality. The tradeoff degrades faster on tasks requiring multi-step reasoning, so this works best when task complexity is predictable.
One reliability improvement worth noting: Opus 4.8 is roughly four times less likely than its predecessor to let its own code errors pass without flagging them, per Anthropic’s release notes. In automated pipelines where downstream steps depend on correct output, silent failures are particularly costly — this change has a larger practical impact than the raw ratio suggests.
Claude Sonnet 4.6
Released in February, Sonnet 4.6 has become the practical choice for most developers according to Claude Code usage data. At $3 per million input tokens and $15 per million output tokens (Anthropic pricing) — 40% less than Opus 4.6 — it scores 79.6% on SWE-bench Verified as of June 2026, within 1.2 percentage points of the more expensive previous-generation Opus model.
That gap narrows further in real-world use. Developers chose Sonnet 4.6 over Opus 4.5 in 59% of head-to-head evaluations inside Claude Code, per ZBuild’s analysis. The performance difference only becomes consistently detectable on tasks involving large multi-repository refactors, complex architectural decisions across unfamiliar codebases, or agentic workflows that require extended planning over many steps. For the majority of professional development work — feature implementation, bug fixes, code review, documentation — Sonnet 4.6 performs at a level that makes the cost difference hard to justify.
Both models support a 1 million token context window, enough to load a full enterprise codebase in a single session
OpenAI: GPT-5.5 Is Designed for Work You Can Walk Away From
OpenAI released GPT-5.5 on April 23, 2026, less than two months after GPT-5.4. The full announcement is available on OpenAI’s blog.
The design goal is explicit. During the announcement briefing, OpenAI President Greg Brockman described it this way: “What is really special about this model is how much more it can do with less guidance. It can look at an unclear problem and figure out just what needs to happen next.”
GPT-5.5 targets long-horizon agentic tasks — workflows where a model must plan, select tools, recover from errors, and continue working for extended periods without repeated prompting. OpenAI’s launch documentation lists its target competencies as: writing and debugging code, researching online, analyzing data, creating documents and spreadsheets, operating software, and moving across tools until a task is complete.
Key specifications confirmed at launch — note that pricing and access tiers change; always verify against OpenAI’s current pricing page:
- Pricing at launch: $5 per million input tokens, $30 per million output tokens
- Context window: 400K tokens in Codex; standard ChatGPT availability varies by plan
- Access: Available to Plus, Pro, Business, and Enterprise subscribers in ChatGPT and Codex; API access opened April 24
Compared to GPT-5.4, the headline differences are in agentic reliability: GPT-5.5 recovers from errors mid-task more effectively, makes more efficient tool calls, and maintains coherence over longer workflows, according to MindStudio’s model analysis.
The model’s error-recovery behavior deserves particular attention. Earlier GPT models would sometimes stall or repeat failed approaches when hitting an obstacle mid-task. GPT-5.5 more reliably detects that an approach has failed and pivots — either choosing a different tool, reformulating the problem, or surfacing the blocker to the user with enough context to resolve it. This matters significantly for unattended workflows.
Where GPT-5.5 trails: Anthropic’s Opus 4.8 holds a clear lead on agentic coding benchmarks (88.6% vs 58.6% on SWE-bench Verified, as of June 2026). Gemini 3.1 Pro leads on abstract reasoning and scientific knowledge benchmarks. GPT-5.5’s strength lies in general-purpose task execution across a broad range of domains rather than maximum performance in any single category.
Google DeepMind: Gemini 3.1 Pro Leads on Reasoning and Science — and It’s Underrated
Gemini 3.1 Pro was released on February 19, 2026, and it is probably the most capable AI model that most people haven’t heard of. The model card is available from Google DeepMind.
The headline numbers from independent benchmarking firm Artificial Analysis are striking: Gemini 3.1 Pro ties GPT-5.4 for the top position on the Artificial Analysis Intelligence Index across 339 evaluated models. On specific benchmarks (scores recorded June 2026, subject to change as models are updated):
- ARC-AGI-2 (abstract reasoning): 77.1% — the highest score of any commercially available model at any price point as of publication
- GPQA Diamond (PhD-level science across biology, chemistry, and physics): 94.3% — the highest recorded score on this benchmark, according to PCMag’s coverage
- Humanity’s Last Exam (broad academic reasoning): 44.4%, ahead of Claude Opus 4.6 (40.0%) and GPT-5.2 (34.5%)
These scores reflect something meaningful about how the model was built. Gemini 3.1 Pro’s lead on abstract reasoning tasks — the kind that require identifying patterns or rules that don’t appear verbatim in training data — suggests stronger generalization rather than just better memorization of benchmarked material.
Multimodal processing
The model supports a 1 million token context window with native multimodal processing across text, images, audio, and video simultaneously. Earlier Gemini models required transcription intermediaries for audio and video inputs; 3.1 Pro handles all four modalities in a unified pass. The practical effect is that a prompt can include a recorded meeting, a PDF report, a screenshot, and text — and the model processes them together rather than requiring the user to pre-process inputs into a single format.
Dynamic thinking
Gemini 3.1 Pro applies what Google calls “dynamic thinking” automatically: it scales its internal chain-of-thought reasoning based on detected task complexity. Simple factual questions receive fast responses; multi-step research synthesis triggers extended internal deliberation before output. The model calibrates depth without developer configuration.
This has a tradeoff worth knowing: on tasks where fast response time matters more than thoroughness — conversational interfaces, simple lookups, single-step tasks — dynamic thinking can introduce latency that isn’t warranted by the task complexity. For batch processing of complex documents or research queries, it’s a genuine improvement.
Where Gemini 3.1 Pro is the right choice: abstract reasoning, scientific literature review, hypothesis generation, multimodal inputs (especially video), and long-document analysis where the full 1M context window is an asset.
Where it trails: Claude Opus 4.6 remains stronger on GUI-based computer use and tool orchestration; GPT-5.3-Codex holds specific advantages in certain coding scenarios.
xAI: Grok 4 and Its Variants Are Closing the Gap — With Aggressive Pricing
xAI has shipped at a high cadence in 2026. Grok 4 launched in July 2025 as xAI’s flagship model. Since then, xAI has shipped Grok 4.1 and Grok 4.3, with Grok 4.3 beta arriving on April 17, 2026.
Grok 4.3 introduced enhanced long-context processing, multimodal video understanding, and improved reasoning over the base Grok 4. According to VentureBeat’s coverage, OpenRouter noted “a large jump in agentic performance” at a significantly lower price point — xAI cut agent tool pricing by up to 50% in April 2026 alone. Verify current xAI pricing at x.ai/pricing before planning deployments.
Real-time information: Grok’s clearest differentiator
Through direct access to X (formerly Twitter) data and live web search, Grok 4 can pull current information from live discussions, breaking news, and trending topics in a way that snapshot-trained models cannot replicate. For use cases involving current events, market sentiment, or real-time social data, this live connection is a meaningful structural advantage — not just a feature difference.
In practice, this shows up most clearly in tasks like: monitoring brand sentiment as it shifts, tracking a developing news story with multiple updates per hour, or identifying emerging discussions around a topic before they reach mainstream coverage. Models trained on static snapshots can’t do this regardless of how capable they are on benchmarks.
Grok 4 Heavy, available through xAI’s premium SuperGrok tier, is the company’s most powerful variant and includes native tool use with built-in web search and external API calling without additional scaffolding.
Where Grok currently trails: Independent benchmarks place Grok 4.3 behind Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro on core reasoning and coding tasks as of June 2026. VentureBeat’s coverage notes that early Grok 4.3 evaluations flagged some performance regressions in coding and reliability issues. The developer consensus as of mid-2026 is that Grok remains a strong choice for real-time information tasks but is not the first pick for complex software engineering or scientific reasoning.
Open-Source AI: DeepSeek, Llama 4, and Qwen Are Making the Case for Running Your Own Model
One of the most significant shifts in AI in 2026 is not happening at the frontier labs — it’s happening in open weights.
According to a May 2026 analysis by Codersera, the current open-source ranking is:
- DeepSeek V4 Pro — ranks first on the Artificial Analysis Intelligence Index among open-weight models (score: 52), and leads among open models on agentic coding tasks
- Qwen 3.6 (Alibaba) — Qwen3.6-27B scores 77.2% on SWE-bench Verified under Apache 2.0 license as of May 2026, making it commercially usable without restrictions
- Llama 4 (Meta) — Llama 4 Scout supports a 10 million token context window at 17B active parameters per inference pass, fitting on a single NVIDIA H100 GPU
What these scores mean in practice
Qwen3.6-27B’s 77.2% SWE-bench Verified score (as of May 2026) sits within 2.4 percentage points of Claude Sonnet 4.6 (79.6%), a commercial model costing $3 per million tokens. The gap is real but narrow — and it’s measured on a standardized benchmark, not on any specific team’s actual workload.
For businesses with high API volumes, data privacy requirements, or specific customization needs, the calculus has changed. A self-hosted Qwen model now delivers frontier-class results on many tasks. The tradeoff is infrastructure overhead: someone needs to provision, maintain, and monitor the deployment. For teams without ML infrastructure experience, the managed API cost is often the better choice. For teams that already run their own compute, the cost savings can be substantial.
The privacy angle is particularly relevant: for healthcare, legal, and financial use cases, a locally hosted model means sensitive data never leaves the organization’s servers. That was not a viable option for frontier-class tasks 18 months ago.
Three forces driving open-source convergence
Efficiency architecture — Models like DeepSeek use Mixture-of-Experts (MoE) architectures that activate only a fraction of total parameters per inference pass. A model with 671B total parameters might activate only 37B per forward pass, dramatically reducing compute cost without proportional capability loss.
Competition-driven improvement — Frontier labs releasing stronger proprietary models has pushed open-source teams to iterate faster and publish more aggressively.
Commercial licensing expansion — Mistral Large 3 and Gemma 4 (Google) are now available under Apache 2.0, the most permissive commercial license, removing the legal barriers that previously made enterprise deployment risky.
What This Year’s Releases Actually Mean for Businesses and Developers
The shift happening across these releases is not subtle: AI is moving from a tool you prompt to a system you deploy.
In 2024, the dominant use case was “ask AI a question, read the answer, decide what to do.” In 2026, the use cases are increasingly “give AI a task, let it plan and execute, review the output.” That is a fundamentally different relationship with the technology — and it requires different evaluation criteria. Response quality on a single turn matters less. Planning coherence, error recovery, tool-use reliability, and long-context faithfulness matter more.
Model selection by use case
All benchmark scores and pricing below reflect data as of June 2026 — in a field moving this fast, verify against current documentation before making deployment decisions.
For software engineering: Claude Opus 4.8 (88.6% SWE-bench Verified, June 2026) is the strongest option for complex multi-file and multi-repository tasks. Claude Sonnet 4.6 delivers nearly identical performance at 40% lower cost and is the better default for most development workflows. The upgrade to Opus is defensible for large-scale refactors, unfamiliar codebases, or extended agentic tasks that run without supervision.
For abstract reasoning and scientific research: Gemini 3.1 Pro leads on both ARC-AGI-2 (77.1%) and GPQA Diamond (94.3%) as of June 2026. If the work involves synthesizing research across large document sets, generating hypotheses from scientific literature, or processing multimodal inputs, this is the model to evaluate first.
For general-purpose autonomous task execution: GPT-5.5 is specifically designed for long-horizon agentic tasks where the model needs to work through ambiguity without repeated prompting. Its error-recovery behavior is particularly strong compared to earlier models.
For real-time information: Grok 4 and its variants are the clearest choice when current information from live web and social data is essential. No snapshot-trained model can match this for real-time use cases.
For cost-sensitive or privacy-sensitive deployments: DeepSeek V4 Pro and Qwen 3.6 are now competitive with commercial models on many benchmarks and can be self-hosted. The infrastructure cost and expertise required are real tradeoffs that vary by team.
A note on benchmark reliability
General benchmarks tell you a lot, but they don’t tell you everything. A model that scores 88.6% on SWE-bench Verified may underperform on a team’s specific stack, coding conventions, or language. A model that leads on GPQA Diamond may not be the strongest choice for a specialized subdomain within biology or chemistry. The most defensible evaluation strategy is to benchmark against a representative sample of your actual workload before committing to a deployment.
The pace of releases also means any “best model” recommendation has a short shelf life. New capabilities ship every few weeks, pricing changes frequently, and different tasks favor different models at different times. Treating model selection as an ongoing evaluation rather than a one-time decision is the approach that holds up.
Methodology
Benchmark figures in this article are sourced from Artificial Analysis (an independent AI benchmarking firm), official model cards published by Anthropic, OpenAI, Google DeepMind, and xAI, and third-party developer evaluations from ZBuild, MindStudio, and Codersera. Pricing figures were verified against official API documentation pages on June 15, 2026 and are subject to change — always verify current pricing before making budget decisions. This article contains no sponsored content and no affiliate relationships with any of the companies covered.
Sources
Official product documentation, pricing pages, benchmark reports, and model release announcements referenced throughout this comparison.
Frequently Asked Questions
Common questions about the most powerful AI models, autonomous agents, coding assistants, and enterprise AI systems in 2026.
The answer depends on the task. Claude Opus 4.8 currently leads in agentic software engineering, Gemini 3.1 Pro dominates abstract reasoning and scientific benchmarks, GPT-5.5 specializes in long-horizon autonomous tasks, while Grok 4 excels at accessing real-time information.
GPT-5.5 is highly capable for coding and autonomous workflows, but benchmark data shows Claude Opus 4.8 performs better on complex software engineering tasks. For many developers, Claude Sonnet 4.6 provides a better balance between performance and cost.
Agentic AI refers to AI systems that can plan and complete multi-step tasks with minimal human guidance. Instead of only answering prompts, these models can use tools, write code, conduct research, analyze data, and adapt when they encounter problems.
Among the models covered in this article, Llama 4 Scout offers the largest context window at up to 10 million tokens. Claude Opus 4.8, Claude Sonnet 4.6, and Gemini 3.1 Pro support 1 million token contexts.
Yes. Modern open-weight models such as DeepSeek V4 Pro and Qwen 3.6 have significantly narrowed the performance gap. They can be strong choices for organizations that need greater privacy, customization, or lower long-term operating costs.
Gemini 3.1 Pro is one of the strongest choices for scientific work because it leads major reasoning benchmarks like GPQA Diamond and performs exceptionally well with long documents and multimodal information.
Cloud APIs are easier to deploy and maintain, making them ideal for most teams. Self-hosting an open-source model can reduce costs and improve data privacy but requires infrastructure, technical expertise, and ongoing maintenance.
Benchmarks measure performance under standardized conditions, but real-world results depend on factors such as a company’s codebase, workflows, industry requirements, and the quality of prompts. The best approach is to test models on your own tasks.
The AI industry is moving extremely quickly. In 2026, major model releases have been appearing approximately every few days, with companies continuously updating capabilities, benchmarks, and pricing.
Businesses should choose based on their specific needs:
- Software engineering: Claude Opus 4.8 or Claude Sonnet 4.6
- Research and scientific analysis: Gemini 3.1 Pro
- Autonomous business workflows: GPT-5.5
- Real-time information and trends: Grok 4
- Privacy and cost-sensitive deployment: DeepSeek V4 Pro or Qwen 3.6








{kind=link}